RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari
Por um escritor misterioso
Last updated 03 junho 2024

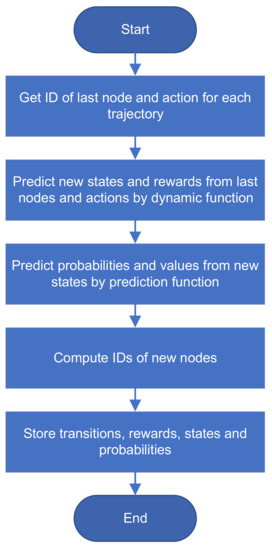
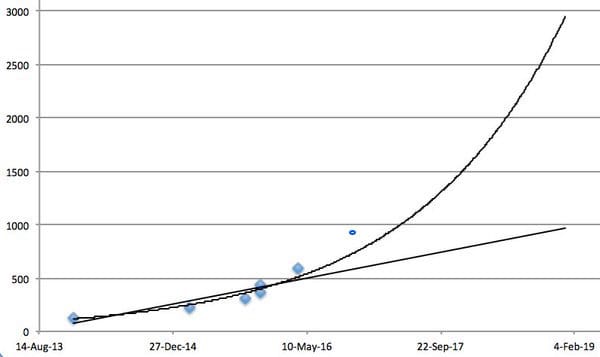
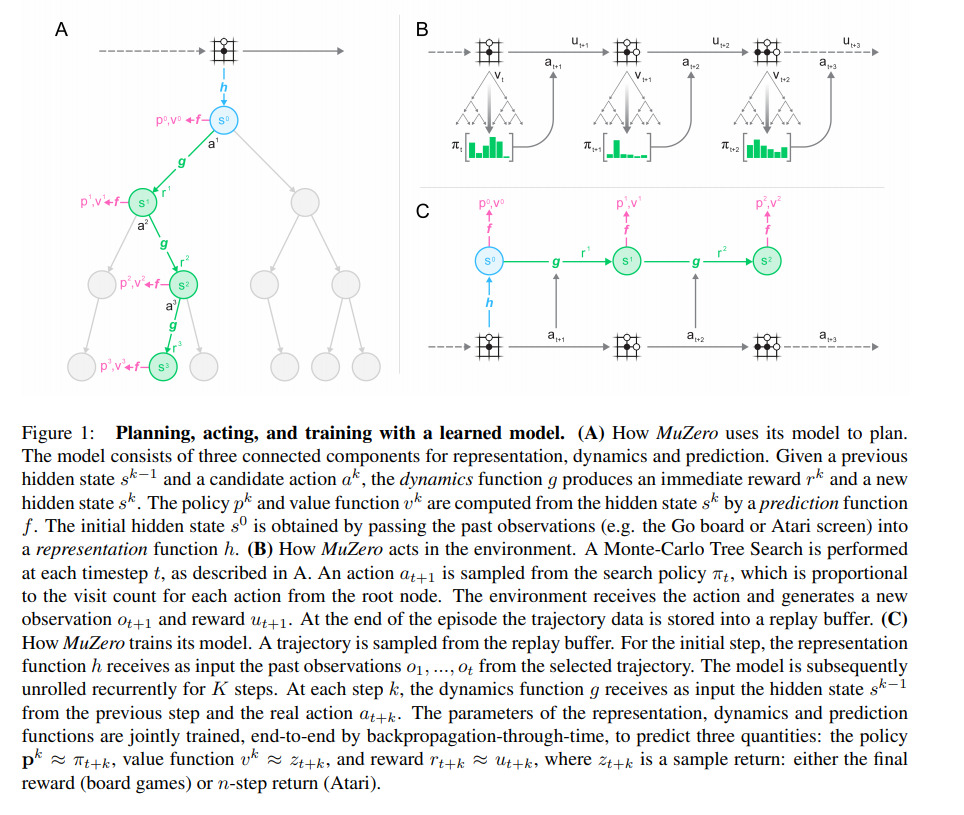
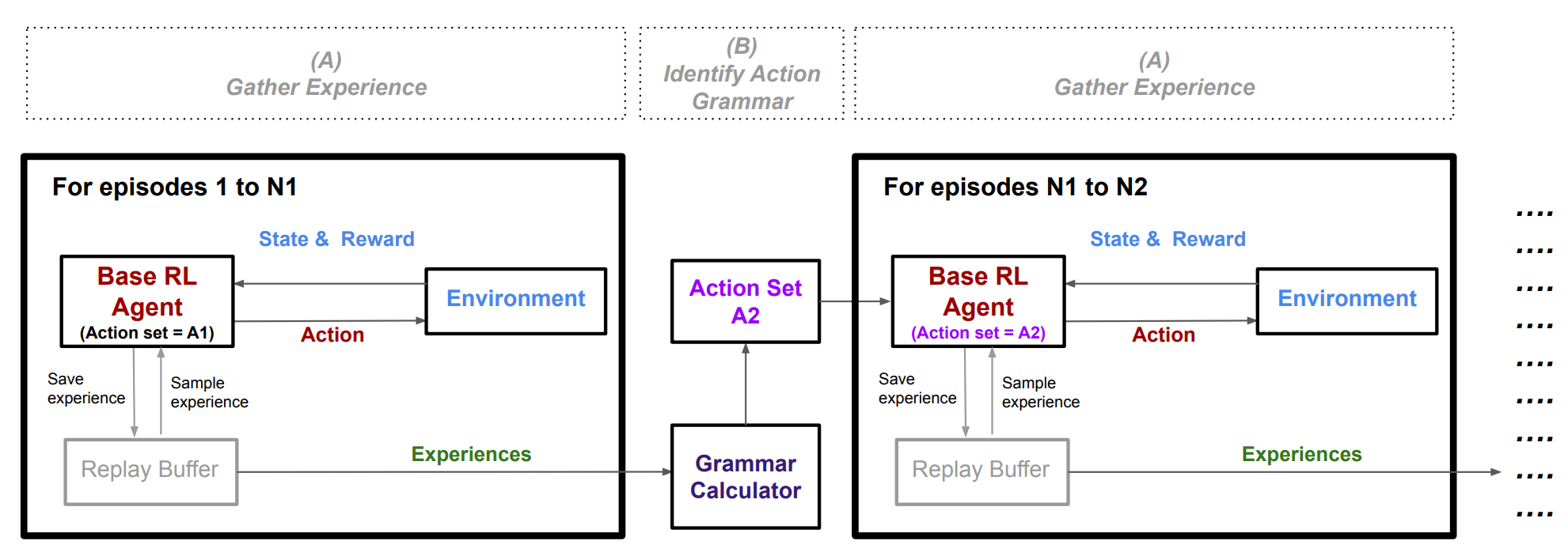
In this issue, we look at MuZero, DeepMind’s new algorithm that learns a model and achieves AlphaZero performance in Chess, Shogi, and Go and achieves state-of-the-art performance on Atari. We also look at Safety Gym, OpenAI’s new environment suite for safe RL.
RL Weekly 36: AlphaZero with a Learned Model achieves SotA in Atari

Home

Scheduling UAV Swarm with Attention-based Graph Reinforcement Learning for Ground-to-air Heterogeneous Data Communication

Memory for Lean Reinforcement Learning.pdf

PDF) Alpha-T: Learning to Traverse over Graphs with An AlphaZero-inspired Self-Play Framework
Applied Sciences, Free Full-Text
All Categories - Miles Brundage
AlphaGo/AlphaGoZero/AlphaZero/MuZero: Mastering games using progressively fewer priors
Home
Recomendado para você
-
 Leela Chess Zero: AlphaZero for the PC03 junho 2024
Leela Chess Zero: AlphaZero for the PC03 junho 2024 -
 AlphaZero: Reactions From Top GMs, Stockfish Author : r/chess03 junho 2024
AlphaZero: Reactions From Top GMs, Stockfish Author : r/chess03 junho 2024 -
 Simple Alpha Zero03 junho 2024
Simple Alpha Zero03 junho 2024 -
 GitHub - kevaday/alphazero-general: A fast, generalized, and03 junho 2024
GitHub - kevaday/alphazero-general: A fast, generalized, and03 junho 2024 -
 GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the03 junho 2024
GitHub - junxiaosong/AlphaZero_Gomoku: An implementation of the03 junho 2024 -
 Time manager Alphazero - Leela Chess Zero03 junho 2024
Time manager Alphazero - Leela Chess Zero03 junho 2024 -
 GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero03 junho 2024
GitHub - CogitoNTNU/AlphaZero: An implementation of AlphaZero03 junho 2024 -
 Train on Small, Play the Large: Scaling Up Board Games with03 junho 2024
Train on Small, Play the Large: Scaling Up Board Games with03 junho 2024 -
 GitHub - pytorch/ELF: ELF: a platform for game research03 junho 2024
GitHub - pytorch/ELF: ELF: a platform for game research03 junho 2024 -
 GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by03 junho 2024
GitHub - Zeta36/chess-alpha-zero: Chess reinforcement learning by03 junho 2024
você pode gostar
-
 Linha do Tempo Marvel da Netflix - Parte 103 junho 2024
Linha do Tempo Marvel da Netflix - Parte 103 junho 2024 -
 Xicara para cafe coquinho com pires bela vista03 junho 2024
Xicara para cafe coquinho com pires bela vista03 junho 2024 -
 PDF) Structural and Biochemical Characterization of AaL, a Quorum03 junho 2024
PDF) Structural and Biochemical Characterization of AaL, a Quorum03 junho 2024 -
 The Most Powerful Demons in Demon Slayer – Superhero Jacked03 junho 2024
The Most Powerful Demons in Demon Slayer – Superhero Jacked03 junho 2024 -
Tekken Tag Tournament 2 - Nintendo Wii U, Nintendo Wii U03 junho 2024
-
 Bandeira Vetorial Bonito Mão Desenhado Cacto Imprimir Com Inspiração Citação vetor(es) de stock de ©tkuzminka 39037315003 junho 2024
Bandeira Vetorial Bonito Mão Desenhado Cacto Imprimir Com Inspiração Citação vetor(es) de stock de ©tkuzminka 39037315003 junho 2024 -
Rolling Loud on X: RL PORTUGAL 2022 SET TIMES LET'S GO!!! 🔥🔥🔥 / X03 junho 2024
-
 Arquivo de Corte Topo de Bolo Maleta de Maquiagem Make – Fofurices03 junho 2024
Arquivo de Corte Topo de Bolo Maleta de Maquiagem Make – Fofurices03 junho 2024 -
 PLATINUM END VAI TER 2 TEMPORADA? CANCELADA? - Platinum End 2 temp03 junho 2024
PLATINUM END VAI TER 2 TEMPORADA? CANCELADA? - Platinum End 2 temp03 junho 2024 -
Como fazer o estilo de skin R6!<3🫶🏻‼️, #roblox #fy03 junho 2024


